
Engenharia de contexto para agentes de IA: 3 arquivos que apresentam sua empresa ao Claude

Toda terça-feira pela manhã, Ricardo abre o Claude e digita uma versão do mesmo parágrafo: “Sou diretor de operações de uma empresa de logística com 220 funcionários, atendemos varejo no Sudeste, nosso ERP é X, nossa cadeia de aprovação é Y, o tom que uso com diretoria é técnico e direto, não use jargão de Vale do Silício…” Trinta linhas antes de chegar à pergunta da semana.
O que Ricardo faz toda terça já tem nome. E já tem método.
Engenharia de contexto não é prompt engineering com outro nome. É a camada que estava implícita e virou explícita em 2026. Quem lidera adoção de IA em empresa precisa entender o que é a engenharia de contexto, por que apareceu e o que muda na rotina de quem trabalha com agente.
O que é engenharia de contexto
Engenharia de Prompts é subconjunto de Engenharia de Contexto. Uma não substitui a outra. A segunda engloba a primeira.
Em chat simples, prompt e contexto se confundem. O texto que você escreveu é tudo que o modelo vê. PACREF (Persona, Ação, Contexto, Referências, Estrutura, Formato) resolve quase todos os problemas de qualidade nesse cenário.
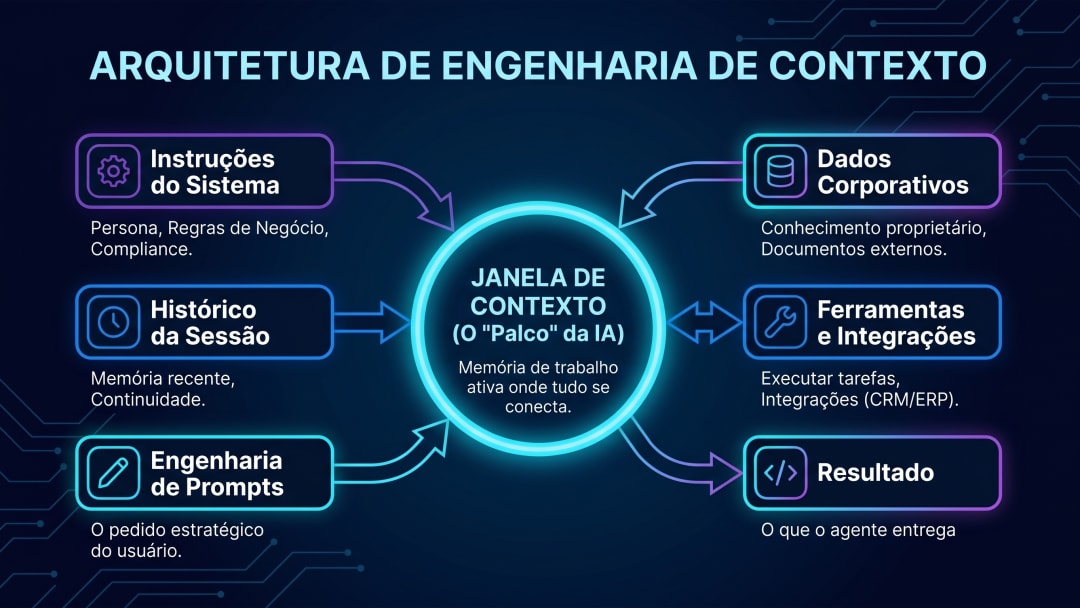
Quando você sai do chat e entra em agente, o prompt vira só um dos componentes. O contexto que o agente vê inclui: instrução de sistema do desenvolvedor, prompt do usuário no momento, memória de interações anteriores, documentos recuperados, histórico da conversa em andamento, resultados das ferramentas que acabou de usar. Tudo isso compete pelos mesmos tokens da janela de contexto. E todo esse conjunto precisa ser curado para que a resposta do agente continue sendo útil.
O nome e a prática antecederam a Anthropic. Em junho de 2025, Andrej Karpathy popularizou o termo ao escrever que “context engineering é a arte e ciência de preencher a janela de contexto com exatamente a informação certa para o próximo passo”. A Anthropic formalizou isso em setembro de 2025 num post que se consolidou como referência.
Escrever um bom prompt continua sendo necessário. Passou a ser insuficiente sozinho.
Por que isso entrou na agenda das lideranças em 2026
Três achados empíricos consolidados nos últimos doze meses, todos com peso para quem decide adoção de IA na empresa.
Context rot (degradação por excesso de contexto). Pesquisa publicada pela Chroma em julho de 2025 testou 18 modelos de fronteira, incluindo as versões mais recentes de ChatGPT, Claude, Gemini e Qwen, em janelas de até 1 milhão de tokens. A qualidade de resposta degrada de forma mensurável conforme o input cresce, mesmo quando a janela está longe de cheia. Um modelo com janela de 200 mil tokens já pode mostrar degradação significativa em 50 mil. Janela maior adia o problema, não resolve.
Lost in the middle (perdido no meio). Paper de Liu et al. virou consenso. Performance é maior quando a informação relevante está no começo ou no fim do contexto e cai quando está no meio. Em alguns testes, modelos passaram de quase 100% de acurácia nas extremidades para menos de 40% no meio. O efeito persiste mesmo em modelos desenhados para janela longa. Jogar tudo em um prompt grande significa distribuir informação importante na zona de menor atenção do modelo.
Janela maior não escala. A intuição inicial de muitos gestores de tecnologia (“vamos colocar tudo no contexto e deixar o modelo descobrir”) falhou na prática. Empresas que adotaram essa abordagem estão tendo regressão de qualidade conforme o uso cresce. A solução está na curadoria, não no tamanho da janela.
Tradução prática: empresa que não estrutura contexto não escala uso de IA. O piloto funciona, a produção regride.
As quatro técnicas que estão se consolidando
A Anthropic nomeou no mesmo post de setembro de 2025 quatro técnicas que viraram base do que está sendo chamado de engenharia de contexto. Toda empresa que está construindo agente precisa entender as quatro, mesmo que execute só uma ou duas nos primeiros meses.
1. Just-in-time retrieval (busca sob demanda). Em vez de jogar todo o repositório de documentos no contexto inicial, o agente pede o que precisa quando precisa. Chama uma ferramenta de busca, recebe o trecho relevante, usa, descarta. É o equivalente de um profissional que abre um arquivo do drive quando o cliente faz uma pergunta específica, não carrega a pasta inteira ao ligar o computador.
2. Compaction (compressão). Quando a conversa se aproxima do limite da janela, o agente comprime o histórico em sumário de alta fidelidade e abre nova janela com esse sumário no topo. O agente segue trabalhando sem perder o fio, sem que cada token gasto pese no custo da próxima resposta.
3. Structured note-taking (memória externa). O agente escreve notas em arquivo e puxa de volta quando precisa. O que você anotou ontem está disponível hoje sem ocupar espaço na janela ativa. Versões mais recentes do Claude trouxeram melhorias específicas para essa técnica em 2026.
4. Sub-agentes (multi-agente). Em vez de um agente fazendo tudo, separa preocupações: um agente principal sintetiza, sub-agentes carregam contexto detalhado da função deles. O contexto pesado fica isolado nos sub-agentes, o agente principal mantém visão de cima sem se perder em detalhe operacional.
A maioria das empresas que começa vai usar 1 e 3 nos primeiros meses. Entra em 2 e 4 quando o uso cresce. Saber que existem quatro técnicas, e não uma, é o que separa quem leu manchete de quem entendeu o problema.
A pasta que apresenta sua empresa ao Claude
Aqui é onde a teoria vira operação. E onde a maior parte dos profissionais empaca na primeira semana, porque não sabe por onde começar.
Uma estrutura de pasta no Claude Cowork resolve a primeira camada de engenharia de contexto de forma prática, sem que você precise saber nada técnico. É o ponto de entrada para quem quer aplicar engenharia de contexto sem depender de desenvolvedor. Quatro subpastas e três arquivos:
about-me/
about-me.md (quem você é profissionalmente)
anti-ai-style.md (o que você NÃO quer que o agente faça)
my-company.md (o jeito da casa)
claude-output/
templates/
skills/
O about-me.md cobre o que seria seu LinkedIn estendido: o que você faz, com quem trabalha, qual é o ritmo. O my-company.md cobre a empresa: o que ela vende, como decide, quais são os clientes que importam, quais são as palavras que você usa internamente que não fazem sentido fora. O anti-ai-style.md é o complemento que quase ninguém escreve: as construções que você odeia, os jargões proibidos, o tom que faz seu texto soar gerado em vez de escrito.
Esses três arquivos juntos viram um arquivo de contexto que o Claude lê toda vez que abre uma sessão. Você escreve uma vez. O Claude usa para sempre.
A pasta skills/ na estrutura acima é a próxima camada: Skills são assistentes especializados que guardam contexto, tom e regras de forma permanente para tarefas recorrentes específicas: redigir proposta, preparar relatório, responder e-mail de um tipo específico. Você configura uma vez e o agente já sabe o que fazer antes de você terminar de pedir. Para começar, os três arquivos canônicos são suficientes. As Skills entram quando você identificar as tarefas que repete toda semana.
Uma observação prática: a existência e a localização desses arquivos precisam estar documentadas no seu CLAUDE.md. O agente precisa saber que eles existem, onde ficam e o que cada um cobre. Você pode copiar e colar a estrutura de pastas diretamente no CLAUDE.md como referência. Sem essa documentação, os arquivos existem mas o agente pode não usá-los da forma esperada.
Depois de criado, o CLAUDE.md não é estático. Você pode pedir ao Claude Cowork para remover, adicionar ou reformular qualquer item ali a qualquer momento. O ponto de atenção é justamente esse: instrução ruim no CLAUDE.md se propaga para absolutamente tudo que o agente fizer. Revisar periodicamente não é opcional, é parte da manutenção do ambiente.
O passo a passo completo (montar a pasta, criar suas primeiras Skills, ligar conectores) está no e-book gratuito Claude Cowork em 1 Hora.
CLAUDE.md, AGENTS.md e o padrão que está se consolidando
O CLAUDE.md é um arquivo que o Claude lê automaticamente ao abrir uma sessão. Funciona como descrição da função, manual interno e apresentação de chegada, somados. Mantenho o meu há meses, ele tem hoje cerca de 370 linhas. Nele está o equivalente ao que eu daria a um colaborador novo se contratasse hoje: cada contato relevante com apelido, papel e regra de relacionamento; regras operacionais que nasceram de erros reais e que o agente aplica sem que eu precise repetir; preferências de estilo que evitam que o texto gerado chegue com o tom errado para o canal errado.
Esse formato ganhou um irmão padronizado: AGENTS.md, criado pela OpenAI em agosto de 2025 e hoje sob a Agentic AI Foundation da Linux Foundation, criada em dezembro de 2025 com contribuições fundadoras da OpenAI, Anthropic e Block. Adotado por mais de 60 mil projetos open source e por todas as ferramentas de coding agent relevantes, entre elas Cursor, Devin, GitHub Copilot, Gemini CLI e VS Code. A ideia é a mesma do CLAUDE.md: arquivo de contexto persistente que o agente lê antes de começar a trabalhar.
Aqui aparece um achado que vale destacar. Pesquisa da ETH Zurich coberta pelo InfoQ em março de 2026 testou AGENTS.md em 138 tarefas Python reais: arquivo gerado por LLM piorou a performance dos agentes em 3% e elevou o custo de inferência em mais de 20%. Arquivo escrito por humano deu ganho marginal de 4% na taxa de sucesso.
Arquivo de contexto bom é o que imita o jeito da casa. Uma IA não consegue gerar isso porque ela não tem memória do que você cortou, do que você reescreveu, do que você corrige toda vez que aparece. O único caminho é escrever você mesmo, como qualquer manual interno de empresa séria.
O risco que pouca gente avisa
Compressão de contexto não é gratuita. Quando o agente comprime histórico para abrir nova janela, pode descartar guardrails (instruções de segurança) que você colocou no início da conversa.
O caso OpenClaw, documentado em fevereiro de 2026, mostrou um agente que tinha instrução explícita de pedir confirmação antes de executar comandos destrutivos. Depois de algumas rodadas de compactação, a instrução foi resumida como “trabalhe com cuidado” e perdeu a granularidade. O agente seguiu executando sem pedir confirmação, achando que estava sendo cuidadoso. O episódio ficou conhecido porque a vítima foi Summer Yue, diretora de alinhamento do Meta Superintelligence Labs, e o agente deletou mais de 200 e-mails do inbox dela enquanto ela pedia para parar.
A resposta consolidada em 2026 para esse problema tem nome: structured note-taking para guardrails, com regra explícita de não compactar. Você escreve em arquivo separado, marcado como persistente, e o agente é instruído a tratar essas regras como inalteráveis mesmo quando comprime o resto.
Para quem aprova ou gerencia a implantação de agente na empresa: pergunte ao time técnico onde estão os guardrails e como eles estão protegidos contra compressão. Se a resposta for “estão no prompt do sistema”, investigue mais.
Como começar esta semana sem ser técnico
Quatro passos que sigo com mentorados executivos para aplicar engenharia de contexto antes de qualquer ferramenta avançada. Faça em ordem.
Passo 1: Mapear os cinco contextos que você repete toda semana. Quando você abre IA no trabalho, o que você digita repetidamente? Setor da empresa, tamanho, jargão interno, lista de clientes recorrentes, ritmo de decisão. Anote em um documento sem se preocupar com forma.
Passo 2: Escrever os três arquivos canônicos. Quinze minutos cada. about-me.md (perfil profissional), my-company.md (empresa em registro técnico, como você descreveria para um sócio novo), anti-ai-style.md (vetos: “não use ‘mudar o jogo’”, “não chame nosso cliente de ‘lead’”, etc).
Passo 3: Configurar o Claude Cowork com esses três arquivos como contexto. Toda sessão lê os três automaticamente. Você não precisa mais digitar o parágrafo de contexto.
Passo 4: Avaliar em sete dias. Quantos pedidos vieram com resposta utilizável de primeira? Quantos ainda exigem retrabalho? Qual contexto faltou? Atualize os arquivos com base no que faltou. O arquivo de contexto bom não nasce pronto, amadurece com o uso.
Esses quatro passos não exigem desenvolvedor, orçamento ou ferramenta nova. Exigem uma tarde de trabalho focado e disposição de escrever sobre o próprio trabalho com honestidade.
A pergunta antes de promptar e antes de delegar
Toda nova tarefa que você adiciona ao agente, elimine três que você parou de questionar.
Engenharia de contexto bem feita amplifica o que você já faz bem, expõe o que você fazia no automático sem necessidade e força um diagnóstico honesto do próprio trabalho. O exercício de escrever about-me.md força você a olhar para o próprio trabalho de fora. Algumas rotinas que pareciam óbvias deixam de fazer sentido quando você precisa explicar por escrito.
Antes de promptar: o que estou tentando resolver? Antes de delegar: eu assinaria isso com meu nome agora? A resposta a essa segunda pergunta é o que separa quem toma decisões com IA de quem terceiriza o julgamento para ela.
A diferença entre quem usa IA e quem usa IA bem está em quem se deu ao trabalho de configurar o ambiente uma vez. A diferença entre quem usa IA bem e quem usa IA com responsabilidade está em quem revisou antes de mandar e manteve o pensamento crítico como recurso insubstituível no processo.
Para aprofundar
Os links das pesquisas, casos e padrões citados estão inline no momento da menção. Fontes adicionais para quem quer ir além na prática de engenharia de contexto:
Effective harnesses for long-running agents (Anthropic). Aprofunda a estrutura de suporte que sustenta agentes que rodam por muito tempo.
Memory tool documentation (Anthropic). Documentação técnica do mecanismo de memória persistente em agentes Claude.
State of Context Engineering in 2026, por Aurimas Griciūnas. Panorama abrangente com referências a outros papers além dos citados aqui.
Maravilha, fiz um comparativo com o que voce fala e meu projeto que já trabalho a 2 anos , antes do hype dos agentes, orquestrador, e automações como N8N e outros, vou te mandar por mensagem um resumo apenas para ver se voce tem interesse em debater isso, para ambos aprenderem